含隐变量的图模型的参数学习(EM 算法)
有些时候 X 中的变量有很复杂的依赖关系,直接建模 p(x) 会很困难,这时通常会引入隐变量 z 来简化模型。如果图模型中包含隐变量,即有部分变量是不可观测的,这时就需要用 EM 算法(Expectation Maximum,期望最大化算法)来进行参数估计。
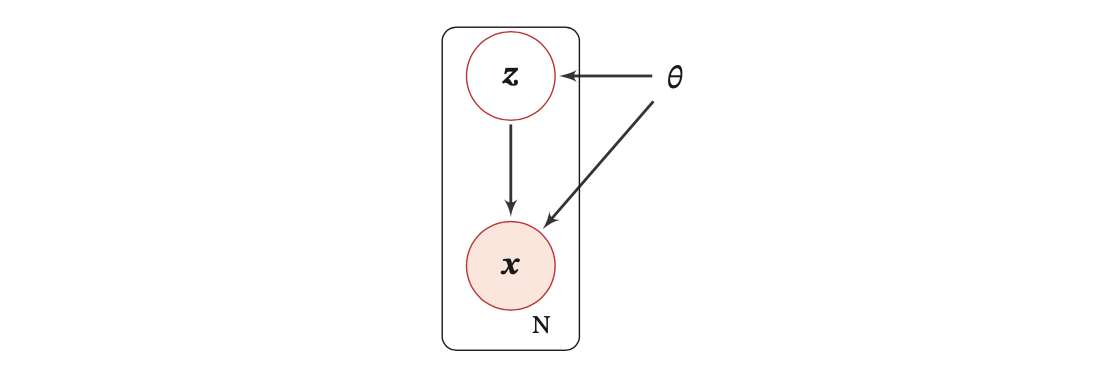
下图为带隐变量的贝叶斯网络的图模型结构,矩形表示其中的变量重复 N 次(因为数据集中有 N 个样本):
边缘似然
令 X 为可观测变量集合,Z 为隐变量集合。由于隐变量不可观测,因此一般改用边缘分布(也就是显变量的分布)的最大似然为目标函数。
样本 x 的边缘似然函数(Marginal Likelihood)为:
pθ(x)=z∑pθ(x,z)=z∑pθ(x∣z)pθ(z)
边缘似然也称为证据(evidence)。
给定 N 个训练样本 D={x(n)}n=1N,其对数边缘似然函数为:
L(D;θ)=N1n=1∑Nlogpθ(x(n))=N1n=1∑Nlogz∑pθ(x(n),z)=N1n=1∑Nlogz∑pθ(x(n)∣z)pθ(z)
ELBO
上式第三步意味着我们要对所有可能的 z 求和(或积分),除非 pθ(x,z) 的形式非常简单,否则这在很多情况下是 intractable 的。因此,为了计算 logpθ(x),我们引入一个额外的变分函数(variational function)q(z),q(z) 是一个定义在隐变量 Z 上的分布:
logpθ(x)=logz∑q(z)q(z)pθ(x,z)=logEq(z)[q(z)pθ(x,z)]≥Eq(z)[logq(z)pθ(x,z)](詹森不等式)=z∑q(z)logq(z)pθ(x,z)≜ELBOθ(q,x)
ELBOθ(q,x) 为样本 x 的对数边缘似然函数 logpθ(x) 的下界,称为证据下界(Evidence Lower Bound,ELBO)。
其中,詹森不等式(Jensen Inequlity)指,对于下凸函数 g,『期望的函数大于等于函数的期望』一定成立,即:
g(E[X])≥E[g(X)]
当且仅当 q(z)=pθ(z∣x) 时,等号成立,即 logpθ(x)=ELBOθ(q,x)。
证明过程如下(《神经网络与深度学习》习题 11-4,不想看证明的话跳过就好):
显然,当且仅当 q(z)pθ(x,z) 的比值为一个常数时,等号成立:
q(z)pθ(x,z)=c(1)
⇒pθ(x,z)=c⋅q(z)
⇒∫zpθ(x,z)dz=∫zc⋅q(z)dz
其中 ∫zpθ(x,z)dz 可以看作是 pθ(x) 的边缘概率;∫zc⋅q(z)dz 可以看作是 c 的边缘概率,从而:
pθ(x)=c(2)
将式 (2) 带入式 (1) 得:
q(z)=pθ(x)pθ(x,z)=pθ(z∣x)(3)
注意,式 (3) 中的 θ 是一个常数值。比如当 EM 算法的第 t 步 argmaxθtpθt+1(x) 时,式 (3) 中的 θ 就是 t−1 步时的参数 θt。
这样,最大化对数边缘似然函数 logpθ(x) 的过程可以分解为两个步骤:
找到近似分布 q(z) 使得 logpθ(x)=ELBOθ(q,x)
寻找能最大化 ELBOθ(q,x) 的参数 θ
这就是 EM 算法。
EM 算法
EM 算法具体分为 E 步(expectation step)和 M 步(maximization step),这两步不断重复,通过迭代的方法来最大化边缘似然。在第 t 步更新时,E 步和 M 步分别为:
E 步:固定参数 θt ,找到一个分布 qt+1(z) 使得证据下界 ELBOθt(q,x) 等于 logpθt(x)
M 步:固定 qt+1(z),找到一组参数使得证据下界 ELBOθt(qt+1,x) 最大,即:
θt+1=argθmaxELBOθ(qt+1,x)=argθmaxz∑qt+1(z)logqt+1(z)pθ(x,z)=argθmaxz∑pθt(z∣x)logpθt(z∣x)pθ(x,z)=argθmaxz∑pθt(z∣x)logpθ(x,z)
θt 为上一时刻的参数,pθt(z∣x) 是 z 的后验分布。
从 KL 散度来理解
对数边缘似然 logpθ(x) 可以分解为:
pθ(x,z)=pθ(z∣x)pθ(x)
⇒logpθ(x,z)=logpθ(z∣x)+logpθ(x)
⇒logpθ(x)=logpθ(x,z)−logpθ(z∣x)
两边同时对隐变量分布 q(z) 求期望,左边:
z∑q(z)logpθ(x)=logpθ(x)z∑q(z)=logpθ(x)
右边可以先写成:
logpθ(x,z)−logpθ(z∣x)
=(logpθ(x,z)−logq(z))−(logpθ(z∣x)−logq(z))
=logq(z)pθ(x,z)−logq(z)pθ(z∣x)
则右边对隐变量分布 q(z) 求期望:
z∑q(z)(logpθ(x,z)−logpθ(z∣x))
=z∑q(z)logq(z)pθ(x,z)−z∑q(z)logq(z)pθ(z∣x)
=ELBOθ(q,x)+KL(q(z)∥pθ(z∣x))
合起来:
logpθ(x)=ELBOθ(q,x)+KL(q(z)∥pθ(z∣x))
其中,KL(q(z)∥pθ(z∣x)) 为隐变量分布 q(z) 和后验分布 pθ(z∣x) 的 KL 散度。
KL 散度一定 ≥0,且当且仅当 q(z)=pθ(z∣x) 时,KL(q(z)∥pθ(z∣x))=0,从而使得 ELBOθ(q,x)=logpθ(x)。
所以 ELBOθ(q,x) 为 logpθ(x) 的一个下界。因此当逐步提高这个下界时,相当于增大了 logpθ(x),所以要对 ELBO 求期望最大化:
θ^=argθmaxELBOθ(q,x)
收敛性证明
直觉上的证明
假设在第 t 步时的模型参数为 θt。
E 步:找到一个分布 qt+1(z) 使得 logpθt(x)=ELBOθt(qt+1,x)
M 步:固定 qt+1(z),找到一组参数 θt+1 使得 ELBOθt+1(qt+1,x) 最大,则有 ELBOθt+1(qt+1,x)≥ELBOθt(qt+1,x)
因此有:
logpθt+1(x)≥ELBOθt+1(qt+1,x)≥ELBOθt(qt+1,x)=logpθt(x)
公式上的证明
我觉得直觉上的证明已经很清楚了...所以公式上的证明我就直接放个链接了。
EM 算法在 GMM 中的应用
参考
