
基本概念
概述
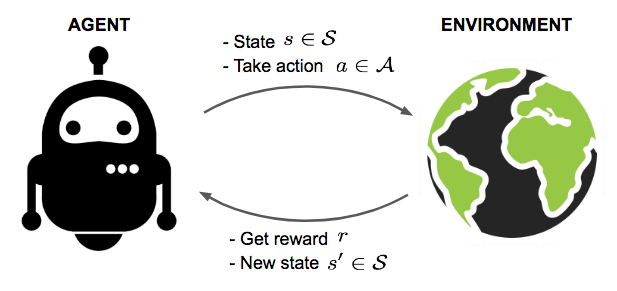
现在有一个智能体(agent)和一个复杂不确定的环境(environment)。智能体会从环境里面获取到当前状态(state)(),根据这个状态,智能体会根据某种策略 (policy)来输出一个动作(action)()。然后环境会根据智能体采取的动作和奖励函数 ,返回给智能体一个奖励(reward)()。环境会怎么对动作进行反馈是由一个模型(model)来定义的,这个模型可能是已知的,也可能是未知的。然后智能体会根据转移概率 (transition function)转移到一个新的状态。
强化学习(Reinforcement Learning)的目标就是,让智能体通过不断的尝试和获得反馈,学习到一个最优策略,从而最大化它能获得的累计奖励 (cumulative future reward),也被叫做回报(return)。
Model-Based / Model-Free
首先是 model-free 和 mode-based 的区别,需要理解的是强化学习中的 model 跟智能体没有关系,model 只跟环境有关,它决定了奖励函数 和转移概率 。因此:
- model-based:已知环境,即已知转移概率和奖励函数,那么可以用动态规划(dynamic programming)来解决问题
- model-free:未知环境
回合与轨迹
对于时间步 ,轨迹(trajectory)是指一个回合(episode)中,智能体观测到的所有的状态、动作、奖励序列:
状态转移概率与奖励函数
model 是对环境的描述,它包含两个部分:转移概率 与奖励函数 。
假设智能体目前处于状态 ,然后它采取了一个动作,并转移到了状态 ,并得到了一个奖励 ,我们可以把这一步表示为:。
转移概率 是一个条件概率密度函数,它表示了在状态 采取动作 ,能转移到状态 并得到奖励 的概率:
而状态转移概率 (state-transition function)消去了奖励这一项,表示在状态 采取动作 ,能转移到状态 的概率:
奖励函数 估计了在状态 采取动作 后能得到的奖励的期望:
回报与折扣
强化学习最大化的是回报 ,也叫累计奖励。回报是从当前时刻 开始到一回合结束的所有折扣奖励的总和:
是一个超参数折扣因子(discount factor),它会给未来的奖励打折扣,越久远的未来的奖励的折扣越大,因为:
- 越是未来的奖励不确定性越大(比如股市)
- 未来的奖励对当下并没有用,比如你现在给我一万块,或是一年后给我一万块,那我肯定选择现在就把一万块拿了
- 不打折扣的话就需要考虑无限的时间步
- 有些马尔可夫过程是带环的,它并没有终结的时候,我们想避免这个无穷的奖励
策略函数与值函数
策略函数和状态值函数都是在强化学习中需要学习的东西。
策略函数
策略函数 (一个条件概率密度函数)会控制智能体根据当前状态 来选择最优动作,从而最大化累计奖励(即回报)。需要注意的是最大化的是累积奖励而不是当前奖励。
策略函数可能是随机策略(stochastic policy function),也可能是确定策略(deterministic policy function):
- 随机策略:
- 确定策略:
动作值函数
之前已经给出了回报 的定义,它是 时刻之后所有奖励的加权和。但在 时刻我们并不知道 的值,此时 仍然是个随机变量,它的随机性来源于 时刻之后的状态和动作 ,而这些状态和动作是有 决定的。
因此动作值函数(action-value function,“Q-value”)会对 关于变量 求条件期望:
动作值函数依赖于当前状态 、当前动作 和策略 。
能让动作值函数最大的策略就是最优策略:
还可以定义一个最优动作值函数:
显然有:
状态值函数
每个状态 还有一个对应的状态值函数 (state-value function),它是动作值函数对当前动作 求期望:
状态值函数 只依赖于策略 和当前状态 ,不依赖于动作,因此它评估了策略 和当前状态 的好坏。
能让状态值函数最大的策略就是最优策略:
最优状态值函数:
显然有:
优势函数
动作值函数减状态值函数就是优势函数(advantage function):