
特殊处理
HMM 输出概率的参数估计为:
其中 为标签 在训练集中出现的次数, 为训练集中在 状态下观察结果为 的概率。
一个问题是,如果单词 没有在训练集中出现过,对任意状态 的 都会为 0。因此对任意包含未出现在训练集中的单词的测试句子 ,有:
所以该模型对这样的测试数据是无效的。
不管训练集有多大,肯定都不可避免的会出现训练集中没出现过的测试单词,所以本节将讨论一个解决这个问题的方法。该方法的核心思想是把训练集中出现频率低的单词和测试集中出现过但训练集中没出现过的单词,映射到一个伪词(pseudo-words)集合。如,把 Mulally 映射到伪词 initCap(首字母大写的单词),把 1990 映射到伪词 fourDigitNum(四位数)。伪词集是手工选择的,尽可能保留了不同单词的拼写特征。下图是一个例子(取自 ref [2.4]):
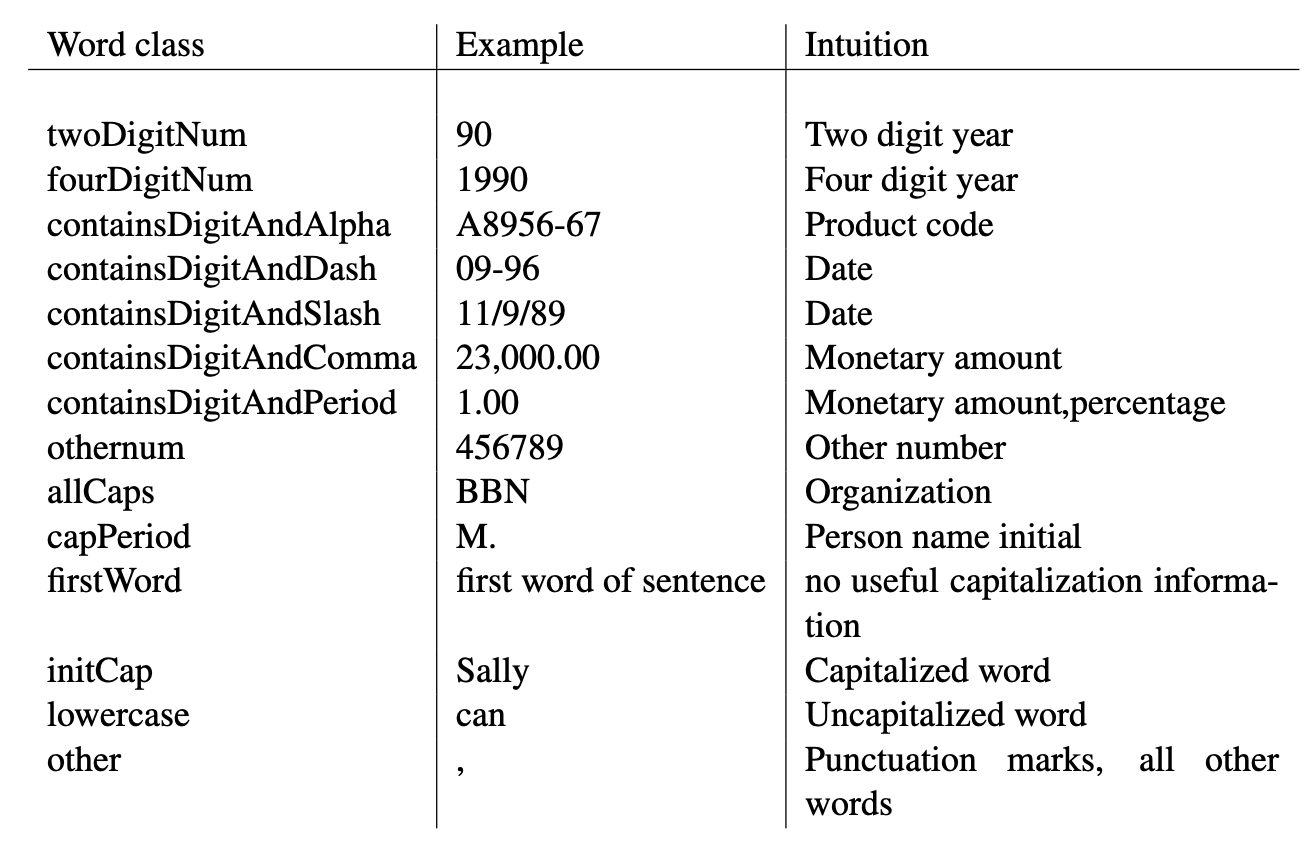
定义 为从单词 到其伪词的映射函数;(一般取 5)为一个界限,在训练集中出现次数低于 的值会被映射到其伪词。测试集中出现过但训练集中没出现过的单词也会被映射到其伪词。这样测试集中的所有单词就都在训练集中出现过了(假设每个伪词都在训练集中出现过,这是比较好保证的), 就不会为 0 了。完成映射后,就可以像之前一样进行参数估计和维比特算法,把其中一些词用伪词替代即可。下图是该映射的一个例子:

但使用这种方法时需要花费较多精力去定义映射,且不同任务中的映射一般都是不一样的。后面我们将讨论更好的解决在训练集中出现频率低或不出现的单词的问题的方法(基于对数线性模型(Log-Linear Models))。